
The team forecasted 85% confidence by the end of Q2.
It shipped mid-Q3.
In the post-mortem, someone leaned back, folded their arms, and said the line that quietly kills every probabilistic practice I’ve ever helped a team adopt:
“So this forecasting stuff doesn’t really work for us, does it?”
Here’s the uncomfortable truth: the forecast did its job. The conversation around it didn’t.
The setup that keeps repeating#
You’ve seen this play out. Maybe you’re living it right now.
A team gets serious about flow. They stop pretending story points were ever a forecasting tool. They start using real data, ranges, and confidence levels. They forecast at 85%, the conservative standard most practitioners settle on, because it gives leadership something they can plan around without anyone pretending the future is a spreadsheet or a crystal ball.
The first few forecasts land inside the range. Confidence in the practice grows. People stop snorting when you say “probabilistic.”
Then one misses. Not by a little. By weeks.
And in the room afterwards, the language quietly reverts. “Can we just commit to a date?” “This isn’t giving us what we need.” “Maybe Monte Carlo is fine for big teams, but…”
Six months of cultural work, gone in one sentence.
Here’s what actually happened#
An 85% forecast that misses is the 15% showing up on schedule.
That’s the model working, not breaking.
Forecast a hundred things at 85%, and you should miss roughly fifteen of them. The whole point of saying “85%” out loud was to acknowledge that the other 15% was real. You priced it in. You named it. You agreed to live with it. So did they (or so you thought).
And then the 15% happened, and everyone forgot they’d agreed.
The room hears “85%” and, silently and instantly, translates it into “definitely, with paperwork.” You smuggled a contract into a probability. The contract broke. The probability did exactly what it said it would.
The bias that does the damage#
There’s a name for what’s happening in that post-mortem.
Annie Duke, the former professional poker player turned decision-making writer, calls it resulting: judging the quality of a decision by the quality of the outcome. They look like the same thing. They aren’t.
A good forecast can have a bad outcome. A bad forecast can have a good outcome. The two are loosely correlated and never identical. Poker players learn this the hard way, because if you judge every hand by whether you won the pot, you’ll start playing terrible cards that happened to win and folding strong hands that happened to lose. Judge the decision. The result is downstream noise.
Most delivery rooms cannot hold this distinction without scaffolding.
Watch the next time something misses. See how quickly the conversation collapses the model into the result. “It missed, so it must have been wrong.” It’s the same logic as “I bet on red, it came up black, therefore betting was a stupid idea.”
You wouldn’t accept that reasoning at a poker table. Don’t accept it in a delivery review.
The four things that could have gone wrong#
When a forecast misses, the room jumps straight to “the model was wrong.” But there are at least four things in play here, and a single data point can’t tell them apart:
The 15% showed up. The model was fine. The unlikely happened. This is the cause people most want to avoid naming, because there’s nothing to fix and nothing (no one?) to blame. It also can’t be proven from a single miss, which is part of what makes it uncomfortable to sit with.
Your system isn’t stable. Cycle times are spread so wide that any forecast becomes a lottery. The model is downstream of a sick system. The forecast is doing its best with the data the system gave it.
Something material changed. New tech, new team, new scope, new dependency. The past stopped predicting the future partway through. The forecast was made with information that later, quietly went out of date.
The model itself was actually wrong. Wrong sampling window, wrong assumptions, wrong base data. This happens, and it’s worth ruling out, but it’s also the cause people reach for first because it’s the most actionable. A miss looks like a maths problem long before it looks like an assumption problem.
A single miss can’t tell you which of the four fired. That’s not a flaw in the list; it’s a property of probability. You need many forecasts and tracked outcomes to make frequency claims about any of these, which is why this post is about how to respond to a miss with discipline rather than how to assign it a cause from one data point.
Three places to look in the conversation#
Three places worth examining alongside the model:
Translation. Nobody in the room knew what 85% felt like in their lives. (Hint: it’s roughly a miss one in seven.) Without a felt reference, percentages are decoration. Try this in your next forecast meeting: “If we ran this same thing seven times, we’d expect to miss it once. We’re betting we’re not in the one.” Watch the energy in the room change.
Pre-commitment. Nobody said “if this misses, here’s what we’ll do” before the forecast was made. So when it missed, the only available script was blame. The fix is small and embarrassing in its obviousness: agree on the response before you need it.
“If the re-forecast pushes past the date by more than a week (or 5%, or whatever band we’ve agreed), we go back to stakeholders the same day, show them the new range, and open the trade-off conversation: move the date, cut scope, or accept the risk.”
Now, a miss has a script.
Two things matter about that trigger. First, the trigger is the next forecast itself. Gut feel doesn’t count. “It feels like we’re slipping” doesn’t fire it. The data does. Which only works if you’re actually doing the next forecast.
Second, the trigger has a tolerance band baked in. Monte Carlo is noisy, especially week-to-week, and a forecast that wobbles a day or two in either direction is what I call Monte Carlo Hula Hula, the model swinging its hips a bit, not the system actually changing. Agree on the band up front, and you stop dragging stakeholders into renegotiations over the wobble. The trigger fires when the drift is real, not when the model is just “dancing”.
Cadence. Most teams forecast at the start and reopen the conversation only when something has already gone wrong. Don’t mistake forecasting for prophecy. Real forecasting is a rolling instrument. Re-forecast often, and re-forecast cheaply. Do it whenever new information arrives. Most of the pain in the post-miss conversation comes from the fact that nobody re-forecasted in the four weeks before the miss became inevitable.
Tighten the range#
Here’s the practitioner move teams almost always miss.
When something misses, the instinct is “let’s forecast at 95% next time, that’ll fix it.” It won’t. All you’ve done is widened the range so the upper bound sits even further out, and bought one more round of “definitely, with paperwork” before the next 5% shows up.
The mature move: keep the confidence level the same, and make the range tighter.
A tighter range comes from a more stable system. Less variation in cycle time. Tighter bounds on work item age. Fewer surprises when halfway home. Less work sitting in queues. The model is downstream of all of this. You fix forecasts by fixing the system the forecast reads from.
If your forecast range is “between three weeks and four months,” look at why your cycle times are spread across a continent. A fancier algorithm won’t help.
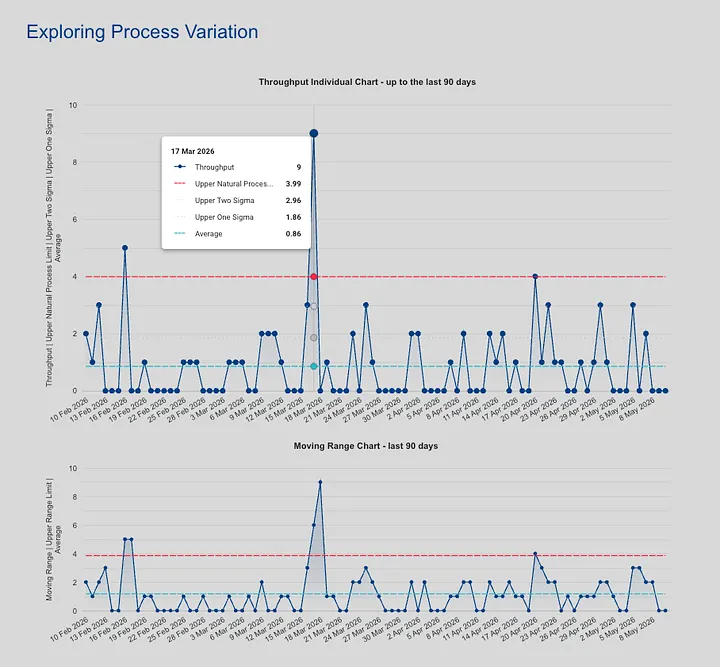
And here’s the practical question that always shows up next: “How do we know when our throughput has actually changed versus when it’s just doing what throughput does?” This is where XmR charts (also called process behaviour charts) earn their keep. Plot your daily throughput, calculate the natural process limits from the moving range, and you get a picture of what routine variation looks like for your team. Anything inside the limits is the system breathing. Anything that breaks through the limits or shows a run of points drifting in one direction is a signal worth investigating.
It’s the same discipline as the tolerance band on the re-forecast trigger, applied one layer deeper. With it, you can finally tell the difference between “our system changed” and “our system is fine, we just had a quiet week.”
The post-miss conversation: a recipe#
When the next forecast misses (and it will, because that’s what probabilistic means), try this:
- Open with the distribution. “We agreed there was a 1-in-7 chance of missing. That’s the world we said we’d accept.” Get the language of probability into the room before the language of blame arrives.
- Separate decision quality from outcome quality. Name the resulting trap explicitly. “A miss inside the range we agreed to means the range was honest.”
- Audit the conversation. What did people hear when you said 85%? What do they need to hear next time?
- Ask whether the system was stable. Stability is whether arrival and departure rates are roughly in balance, and whether the variation you’re seeing is common cause (the system breathing) or special cause (something actually changed). Put your throughput on an XmR chart. Pull up work item age. Look at the cycle time spread. If arrivals are outpacing departures, your queues are quietly filling up, and every future forecast will drift right. If the XmR shows a signal you missed, the forecast wasn’t reading from the system you thought it was. If those charts are a mess, you have a flow problem wearing a forecasting costume.
- Pre-commit before the next forecast. Agree on what happens on a miss before the miss happens.
If you do nothing else, do the first one. It rewires the room.
What this is really about#
The team that survives the first miss is the team that learns probabilistic literacy lives at the leadership layer.
The room ran out of tolerance for uncertainty before the forecast did.
That’s a leadership problem dressed up as a forecasting problem. Because the team can do everything right (run good simulations, present honest ranges, name confidence levels) and one leader saying “just give me a date” in the wrong meeting will untrain the lot of them in thirty seconds.
Calibrated confidence is grown-up thinking. Grown-ups sometimes miss too.
The practice survives if the conversation does its job.
Bringing it home#
Pull up your last missed forecast and ask three honest questions:
- Was the miss inside the confidence range we agreed to?
- Did anyone in the room translate “85%” as “definitely”?
- What did we change after the miss: the model, or the conversation?
If you changed the model, you fixed the wrong thing.
The forecast was probably right. The conversation was wrong.
Stop tuning the maths. Start tuning the room.


